Ontology
The term ontology, as used in our context, refers to a formally specified conceptualisation of a certain research domain that is focused on answering the question of what can and needs to be represented in this domain. An ontology thus defines a collection of technical terms that can be used to semantically describe research data in a FAIR and machine-readable way by the means of annotating the research data with these technical terms. This is best done automatically behind the scenes by your everyday work apps like the ELN. However, as automated ontology-based annotation is not the standard yet, as ontologies evolve with the new insights gained from research, and, as they might contain term definitions which a domain expert (e.g. a chemist like you) might disagree with, knowing the core concepts of ontologies in ones research domain is helpful in a FAIR RDM context. To get an overview of different ontologies or to work with them, one can use different web services, such as the *NFDI4Chem Terminology Service.
Introduction
YouTube uses cookies and stores personal data. To view embedded videos from YouTube, please indicate your consent to load this video from an external source. Your decision will be saved for this session.
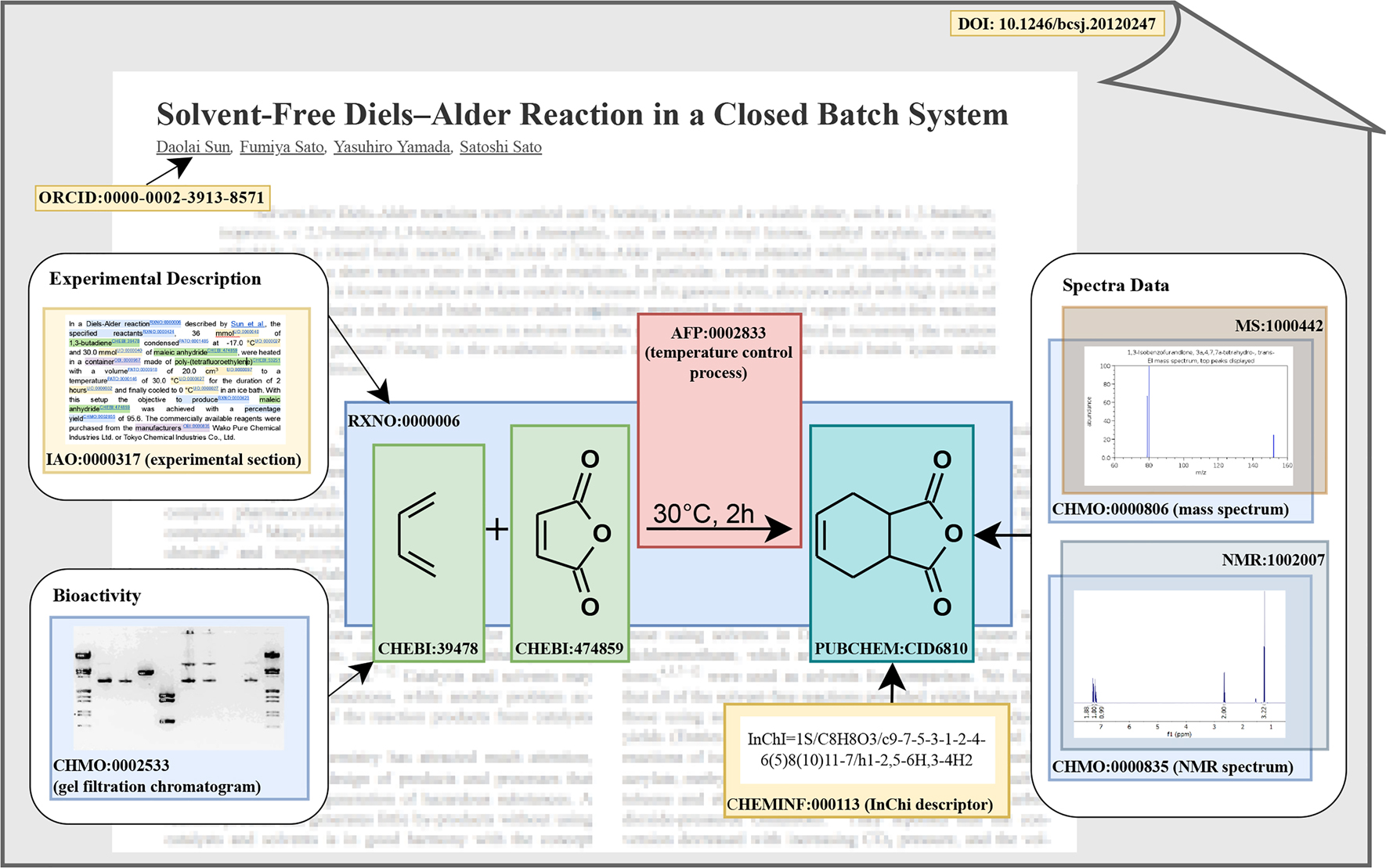 Image Attribution: Philip Strömert, Oliver Koepler, Johannes Hunold, Steffen Neumann, CC BY-NC-ND 4.0
Image Attribution: Philip Strömert, Oliver Koepler, Johannes Hunold, Steffen Neumann, CC BY-NC-ND 4.0
Research data is more than the aggregation of numbers or images in a scientific journal article, experimental section, or supplementary information. To fully reproduce the deduction of the results, we need access to the raw data and how it was generated, processed and analyzed. While humans can grasp all the semantics and knowledge expressed in articles and their experimental sections, computers can not do so without fine grained metadata annotations. As can be seen exemplarily in the graphical abstract above, ontologies, taxonomies, terminologies or controlled vocabularies can be used to semantically describe research data, producing this FAIR and machine-readable data. Quite a few ontologies already exist for the semantic description of general scientific concepts and relations, as well as for chemistry specific ones. Based on an analysis done in Task Area 6.1 of the NFDI4Chem project, the present article provides a commented selection of those ontologies that seem most suitable for a FAIR RDM in chemistry, as well as a very brief glossary of ontological technical terms.
Graphical overview of chemical ontologies
This graphical overview shows chemistry specific ontologies suitable for a FAIR RDM with regard to their position in the BFO/OBO Foundry framework.
 Image Attribution: Philip Strömert, CC-BY 4.0
Image Attribution: Philip Strömert, CC-BY 4.0
Here we can see that these ontologies have different scopes, which means they only provide terms for the representation/conceptualisation of certain aspects of reality (e.g. ChEBI only covers chemical material entities and their roles). Some have a rather narrow scope, some have a broader scope and sometimes these scopes overlap.
Tabular overview of chemical ontologies
This tabular overview lists the suitable ontologies with regard to:
- their general research domain,
- their open access licence,
- the possibility of reusing them in a modular way (whereas a BFO alignment and OBO compatibility indicates an increased possibility),
- and, their use in known applications.
| Ontology | Domain | Licence | Modularity | Used in |
|---|---|---|---|---|
| ChEBI | chemistry | CC-BY 4.0 | BFO & OBO based | YMDB, HMDB, PubChem, MassBank, KNApSAcK, UM-BBD, GMD, SMID-DB |
| CHIRO | chemistry | CC0 1.0 | BFO & OBO based | unknown |
| ChemOnt | chemistry | custom OA licence | subsumable under BFO's material entity | YMDB, HMDB, T3DB, ECMDB, DrugBank,PubChem, ChEBI, LIPID MAPS, MoNA |
| CHEMINF | chemistry | CC-BY 3.0 | BFO & OBO based | PubChem, Open PHACTS |
| CHMO | chemistry | CC-BY 4.0 | BFO & OBO based | Chemotion, Allotrope™ |
| MOP | chemistry | CC-BY 4.0 | BFO & OBO based | RXNO |
| RXNO | chemistry | CC-BY 4.0 | BFO & OBO based | NameRXN, Wikipedia, Chemotion |
| OntoKin | chemistry | MIT | OntoCAPE upper level & modules | J-Park Simulator |
| AFO | chemistry | CC-BY 4.0 | BFO classes & relations, many AFO- some custom OBO-modules | Allotrope™ |
| PROCO | chemistry | CC-BY 4.0 | BFO/AFO & OBO based | Allotrope™ |
| MS | chemistry | CC-BY 4.0 | BFO & OBO mapping possible | mzML |
| nmrCV | chemistry | Public Domain Mark 1.0 | BFO & OBO mapping possible | MetaboLights, HMDB |
| BFO | upper level (classes only) | CC-BY 4.0 | OBO backbone | >300 ontologies & >50 organizations, PubChem |
| RO | upper level (relations) | CC0 1.0 | BFO & OBO based | Monarch Initiative, OBO Foundry, Gene Ontology, PubChem |
| IAO | information artefacts | CC-BY 4.0 | BFO & OBO based | OBO Foundry, Allotrope™, PubChem, ISA tools |
| OBI | biomedicine | CC-BY 4.0 | BFO & OBO based | OBO Foundry, Allotrope™, PubChem |
| UO | scientific units | CC-BY 4.0 | BFO & OBO based | OBO Foundry, UOM, PubChem |
| QUDT | scientific units | CC-BY 4.0 | BFO & OBO based mapping possible | openPHACTS |
| PATO | phenotypic & physical qualities | CC-BY 3.0 | BFO & OBO based | OBO Foundry, Allotrope™ |
| SIO | upper level | CC-BY 4.0 | BFO alignment | PubChemRDF, Bio2RDF, SADI Semantic Web Services, DisGeNET, EBI's Gene Expression Atlas, Graph4Code project |
| EDAM | life-sciences & data management | CC-BY 4.0 | BFO & OBO mapping possible | EMBOSS, Bio-jETI |
| OntoCAPE | upper level & engineering | GNU GPLv2 | provides upper level concepts | J-Park Simulator |
General Scientific Ontologies
BFO
The second version of the Basic Formal Ontology (BFO 2.0) is used as the upper framework by the The Open Biological and Biomedical Ontology (OBO) Foundry. Hence, all ontologies that are part of the OBO Library or that strive to be compatible with OBO need to be aligned to this BFO version. Although the specification reference of BFO 2.0 includes relations, their temporal aspects cause problems, which is why in the OWL implementation of the BFO 2.0 specification the OBO community decided to only use the BFO 2.0 classes and to curate some of its core relations in the OBO Relation Ontology. In order to become an ISO Standard, the BFO developers have released a newer version called the BFO 2020 that also includes relations. Since these relations still use the previously critiqued temporalized approach, the OBO community has not adapted BFO 2020 as its upper framework so far.
SIO
The Semanticscience Integrated Ontology (SIO) is another upper level ontology that provides basic concepts (e.g. objects, information and processes) as well as their associated basic characteristics (e.g. functions, qualities and roles). It also contains many basic relations (e.g. part of, has participant or is about) needed in the description of real objects, processes and information. It has been used in Bio2RDF, SADI Semantic Web Services, DisGeNET, PubChemRDF, EBI's Gene Expression Atlas and the Graph4Code project. To foster semantic interoperability, SIO is mapped to BFO and RO for important core classes and relations.
OntoCape
The ontology for computer-aided chemical process engineering (OntoCAPE) defines fundamental concepts and relations such as data structures, part-whole relations, processes, material, time and space or SI units. OntoCAPE is designed to be reusable and extendable in many different contexts of computer-aided process engineering, without the need for other ontologies. However, as of yet, no evidence could be found to indicate that the meta, upper and conceptual layers of OntoCAPE are being used outside of the network in which it is being developed. Similarly, we could not find any references regarding the interoperability between BFO based ontologies and OntoCAPE.
RO
The Relation Ontology (RO) is the reference ontology of the OBO Foundry for general relations that can be reused in many different contexts (e.g. part of, has characteristic or occurs in). It is thus the place to go to whenever one looks for or needs to contribute OBO compliant relations.
OBI
The Ontology of Biomedical Investigations (OBI) is another prominent OBO ontology that contains many of the common scientific terms needed to describe an investigation or experiment, including its protocols and measuring or assay methods and the equipment used in these planned processes.
IAO
The Information Artefact Ontology (IAO) is the reference ontology of the OBO Foundry for all those entities (e.g. symbol, document, data item or is quality measurement of) that are somehow ‘about’ other entities and that we need to describe information in a machine-readable way.
PATO
The Phenotype And Trait Ontology (PATO) is the reference ontology of the OBO Foundry for all general physical qualities, such as temperature or weight.
EDAM
The Ontology of bioscientific data analysis and data management (EDAM) covers research areas (topics), types of data, data formats, a categorisation of algorithm functionality and also aspects of biochemistry and analytical chemistry. It is not aligned with any upper ontology, but widely used in the life sciences to annotate tool registries (Bio-jETI) or the ELIXIR training portal (TeSS).
UO
The Unit Ontology (UO) is the reference ontology of the OBO Foundry for the SI and derived units that are needed for the proper description of measurements.
QUDT
The ontology of Quantities, Units, Dimensions and Types (QUDT) is a non OBO compliant ontology that specifies quantities and units of measure.
Chemistry Domain Ontologies
ChEBI
The Chemical Entities of Biological Interest (ChEBI) ontology from the European Bioinformatics Institute (EMBL-EBI) is probably one of the most widely used ontologies in the chemical domain, as it provides a comprehensive and well-documented classification of chemical entities. The scope of ChEBI can be subdivided into three ontology modules. The first module, which is the branch that is subsumed under the BFO class material entity, covers the chemical entities atom, group, chemical substance and molecular entity. CHEBI’s second ontology module, the branch that is subsumed under the BFO role class, covers the roles chemical entities can have (be a bearer of) when used or studied in a chemical, biological or an application context (e.g.acid or base role, catalyst etc.). The third module covers subatomic particles. Serving as the data model for the ChEBI database the ontology also demonstrates its importance to modern chemistry by the many databases it cross-references, such as Human Metabolome database (HMDB),the Golm metabolome database, MassBank, KNApSAcK, UM-BBD, SMID-DB and the Yeast Metabolome database (YMDB), or the many ontologies that reuse terms from or map to it. New chemical entities can be added to ChEBI easily via an online submission tool. The correctness of such submissions will then be validated by the ChEBI curators.
ChemOnt
An alternative vocabulary to ChEBI for the classification of chemical compounds is the taxonomy ChemOnt. ChemOnt has originally been developed for ClassyFire, which is widely used for automatic classification of especially organic chemical compounds. Since ChemOnt is only a taxonomy, it lacks relations and axioms to further formalize the chemical knowledge it contains. Thus, it only provides the categories (classes) that are needed by ClassyFire. The actual rules/logic behind the application’s automated classification is encoded into its software. Considering the reusability of ChemOnt it needs to be mentioned that it is neither aligned to BFO like the OBO ontologies, nor to any other upper level ontology. One could subsume ChemOnt’s root category chemical entities under the BFO material entity branch and thus make it reusable in a BFO context. However, as only the chemical compound classes based on structural elements are conceptualized in ChemOnt, it is less granular as ChEBI, which conceptualizes the actual chemical compounds.
CHIRO
The ChEBI Integrated Role Ontology (CHIRO) is a demonstration of how to make the implicit knowledge contained in ChEBI’s role branch explicit by axiomatization. It provides links to other OBO ontologies,such as GOPRO, NCBITaxon, HP or DOID through the use of ad-hoc relations, such asagonist_oforinhibitor_of. The motivation is to establish direct connections between chemical structures such as small molecules or drugs and their effects. CHIRO can thus be used as an ontology module that extends or enhances ChEBI’s role branch. As further development or maintenance of CHIRO is on hold at the moment, it should be considered an important reference point and an opportunity for collaboration once the need to use formalized chemical roles arises.
CHEMINF
The Chemical Information Ontology (CHEMINF) is intended to serve as a single point of truth for the definition and disambiguation of terms and relations used in the domain of cheminformatics. Its scope covers chemical graphs and their various encoding formats, the definition of chemical descriptors, such as InChI or SMILES, commonly used software and algorithms, like the PubChem software library or Lipinski rule of five violation calculation algorithm, as well as format specifications for chemical data, such as the MOLfile format specification. CHEMINF also defines needed chemical qualities, such as _molecular structure _ or charge, as well as dispositions of chemical entities, like solubility or electronegativity. Being a highly expressive ontology, the provided axioms of CHEMINF further specify the covered entities in a machine-readable way. CHEMINF must be considered a required resource whenever there arises the need of describing the various properties of chemical entities, their measurements or predictions, as well as the software and standards used to express these. Its impact is visible in prominent applications such as, the semantic annotation of PubChem’s database, or in the Open PHACTS project.
CHMO & MOP & RXNO
The OBO compliant Chemical Methods Ontology (CHMO), Molecular Process Ontology (MOP) and Named Reactions Ontology (RXNO) have been developed under the auspices of the Royal Society of Chemistry (RSC) starting around 2008 and were initially created with the aim to enhance semantic publishing in the RSC Project Prospect. (see also https://doi.org/10.1021/bk-2014-1164.ch013)
CHMO focuses on the conceptualization of experimental methods applied in chemistry. It extends OBI and IAO with classes that conceptualize needed assays methods, such as spectroscopy, thermal analysis (including calorimetry) or magnetic resonance method, as well as lab devices, substances and protocols (e.g. distillation, buffer solution or hazard reduction). For the axiomatisation of its classes CHMO reuses chemical entities defined in ChEBI and relations from OBI as well as BFO. However, the latter should best be substituted with corresponding RO relations instead to avoid interoperability issues (see also BFO).
MOP focuses on the conceptualization of general molecular processes, such as addition reaction,cyclization or polymerisation. It is thus a rather small ontology that mainly serves as a basis module for the Named Reaction Ontology (RXNO), in which these fundamental molecular processes are needed for the definition of the more complex reactions. Similar to CHMO, the definitions and synonyms defined in MOP are mostly derived from and linked to their respective IUPAC Gold Book entries. In MOP itself, only the relation is_catalysis_of is defined and only used to formally define the class catalysis. Also similar to CHMO, chemical entities from ChEBI are reused for the axiomatization of certain molecular processes.
RXNO expands the molecular processes defined in MOP to cover synthetic organic reactions with small-molecules, such as the well-known Diels-Alder cyclization. The top level classification of RXNO contains reactions that change the skeleton (e.g. cleaving, condensation, rearrangement), as well as reactions that preserve the skeleton (e.g. addition, elimination, protection or deprotection). The classification of named reactions in RXNO is based on two principles, first comparing the longest carbon chains in the reactants and products and then checking whether a ring system is created, broken or altered. For the formalization of its classification, RXNO also reuses chemical entities from ChEBI as well as classes from OBI and IAO. The use of OBO unsupported BFO relations is, as in the other two RSC ontologies, also in RXNO a minor issue that should be solved. Another rather easily resolvable issue concerns the current chosen import strategy of MOP classes, as it leaves room for curation errors. A flowchart and documentation on how to classify named reactions in RXNO allows an open source based community collaboration and thus a timely addition of not yet covered reactions.
OntoKin
The Ontology for Chemical Kinetic ReactionMechanisms (OntoKin) is intended to be used for the simulation and understanding of the behavior of chemical processes and can be seen as a domain specific extension of the OntoCape ontology. Its scope can be divided into five modules: reaction mechanism, phase, chemical reaction, rate coefficient and chemical species. These modules define the classes (e.g.,BulkPhase or GasPhaseReaction), relations (e.g.,hasElement or belongsToPhase), and axioms (e.g.,ChemicalReaction always has a Reactant, Product, ReactionMetadata, ReactionOrder and StoichiometricCoefficient) that are needed for a comprehensive semantic description of reaction kinetics. From OntoCAPE the classes ChemicalReaction,ChemicalSpecies,ReactionRateCoefficient,ThermoModel and StoichiometricCoefficient are reused, but no terms from other chemical ontologies are reused. Thus, OntoKin on the one hand has the advantage of having very few external dependencies, which makes it robust in terms of semantic stability and easier to implement in applications, such as the prototype of an open access knowledge graph. On the other hand however, these few dependencies also means that data described with OntoKin is not as interoperable as data described with an OBO compliant ontology. The lack of meta-information for OntoKin's terms as well as its sparse documentation in general might be a possible hindrance for users.
AFO
The Allotrope Foundation Merged Ontology Suite (AFO), first published in March 2018, is a collection of taxonomies and ontologies developed by the Allotrope Foundation that is intended as a standard language for describing equipment, processes, materials, and results. AFO provides the semantic context in a technology stack, called Allotrope Framework, which also consists of the Allotrope Data Model (ADM) and the AllotropeData Format (ADF). The goal of ADF is to unify the laboratory IT landscape by becoming the gold standard with regard to the many different data formats present today. According to Millecam et al., its adoption is still at the very beginning. An out of the box modular reuse of Allotrope’s ontology suite along with OBO based ontologies might lead to problems, as there certain design related differences, such as AFO's strict principle of single inheritance, which means that a class in AFO cannot have multiple parent classes, its not so well documented import strategy of BFO as well as classes and relations from other OBO ontologies, or the fact that AFO reuses the BFO 2020 ISO version including its temporalized relations (see lso BFO).
PROCO
The Process Chemistry Ontology (PROCO) describes the domain of process chemistry from route scouting, process optimization, process validation and process maintenance with key concepts like product quality, production processes, environmental sustainability, regulatory compliance, and safety. This BFO aligned ontology is currently being developed as a joint venture between academia (University of Michigan) and industry (Merk, GSK, Allotrope Foundation). In order to foster the collaboration between the Allotrope Foundation and the OBO community, PROCO was submitted for review to the OBO foundry in April 2021. Following a button-up approach in the definition of certain terms, the PROCO developers identified standardized lab practices and basic process patterns that are explicitly or implicitly present in Allotrope's data model as well as in the specifications of regulatory agencies. PROCO reuses terms from chemical ontologies, such as CHMO and ChEBI, alongside other needed common OBO and non OBO terms (mainly from AFO and SIO). Due to PROCO's scope, the fact that this is a cooperation between industry and academia, and the intention to integrate PROCO as a module in the Allotrope framework with the aim to improve industrial production, means that future developments should be monitored. Also being a “community-based ontology”, makes PROCO a great candidate for reuse.
MS
The Mass spectrometry ontology (MS), developed under the Human Proteome Organization Proteomics Standards Initiative (HUPO-PSI), focuses on the description of mass spectrometer output files and the interpretation of mass spectra, with the two most important branches anchored in the root classes spectrum generation information and spectrum interpretation. The other ten branches contain the classes needed to represent related concepts (e.g. molecular entity, software or regular expression). They are either differentiated into finer subclasses (e.g. atom, Brucker software or Cleavage agent regular expression), or associated with conceptually similar classes using the MS part_of relation. For example, the molecular entity attribute class, which is defined as part of the molecular entity class, provides in its subclasses the attributes needed to further describe a molecular entity (e.g. SMILES formula). This partonomy structure provides a grouping of concepts that is directly usable in the software that generates the XML based files that encode MS experiment information. For the representation of other common qualities needed in this domain, MS directly imports PATO, and for SI units as well as common quantity prefixes it directly imports UO. Undocumented are the reasons why semantically similar classes are not reused from or aligned with other external ontologies (e.g. SMILES formula or InchiKey in CHEMINF, or all the same molecular entities in ChEBI).
nmrCV
The scope of the nuclear magnetic resonance CV (nmrCV) is the conceptualisation of terms needed in the description of nuclear magnetic resonance (NMR) assays. It is developed by experts from the Metabolomics Standards Initiative (MSI) under the governance of the COSMOS EU and PhenoMeNal EU projects and maintained on GitHub. Being designed as a simple taxonomy, nmrCV has no object or data properties. Its primary application context, is the creation and validation of XML files storing NMR assay data in the nmrML file format. With regard to its modularity, it can be noted that nmrCV is BFO-based, but otherwise does not really follow the OBO core principle of reusing as much as possible from existing OBO ontologies. For example, such general classes as software and instrument are defined in nmrCV instead of being reused from IAO or OBI. The same is true for some of the domain specific concepts such as* NMR pulse sequences* or NMR instruments, for which there are already equivalents in CHMO. A mapping to such close or exact matches in other ontologies is also not provided. This might be hindering a direct reuse of nmrCV in different application contexts. A semantic harmonization with the existing OBO ontologies, especially with CHMO, is thus a needed improvement to enhance interoperability.
FIX & REX
Although the two chemistry related ontologies Physico-chemical methods and properties ontology (FIX) and Physico-chemical process ontology (REX) are indexed in the NFDI4Chem Terminology Service, reusing them should be done with caution, as they are no longer maintained and thus considered "orphaned" according to the OBO Foundry. Most of the concepts defined in these two ontologies can also be found in the more current and well maintained ontologies CHMO, MOP and RXNO.
Glossary
In order to be able to speak about the existing ontologies in the domain of chemistry, we need to provide a very brief glossary of the most important technical terms that describe an ontology:
- classes represent those portions of reality that exist as generic entities, such as atoms and molecules, chemical reactions, lab equipment and experimental methods (e.g. the class MassSpectrometer)
- instances, individuals or particulars of a class are particular entities that exist in reality, (e.g. a particular mass spectrometer identified via a serial number)
- relations or properties are terms used to signify the interdependence between classes or individuals (e.g. a specific molecule participates in a certain chemical reaction)
- taxonomy refers to a hierarchical structuring of classes into superclasses and subclasses (e.g MassSpectrometer is_a Device or HomoSapiens is_a Mamal)
- axioms are the rules defined to express relations that always hold true between classes or instances of classes (e.g. MolecularProcess is a process that must have one or more MolecularEntities as its participants)
- upper ontologies conceptualize the most general parts of reality (e.g. time, space, material matter, process, causality, parthood, etc) and thus can provide a semantic framework for domain or application ontologies ** In a best case scenario there is only one upper ontology to be used by many domain ontologies to ensure their interoperability
- domain ontologies conceptualize specific aspects of a given domain (e.g. ChEBI conceptualizes only chemical entities like atoms and molecules as well as their roles in certain contexts)
- application ontologies are domain ontologies that are implemented in a concrete application and thus limited to the applications use cases
Sources and further information
written by: https://orcid.org/0000-0002-1595-3213